

インテル® Trace Analyzer/ Collectorについての概要
インテル株式会社主催の「インテル® Trace Analyzer/ Collector を使ったMPI アプリの性能解析」が平成24年9月13日(木)13時から17時まで計算科学センタービル2階実習室にて行われました。
本セミナーは4月、6月に続き3回目の開催となりました。3名の方に参加いただきました。受講者は1人1台の端末を使い、アプリケーションの最適化を効率よく行うためのTrace Analyzer/ Collectorの使い方を学ばれました。
今回は、特別講師として株式会社爆発研究所の荒川氏が加わりました。前半は荒川氏によるMPIアプリケーションの性能改善例についての講義があり、後半はエクセルソフトの黒澤氏によるTrace Analyzer/ Collectorについての概要の解説及び実習が行われました。
受講者には、インテル® ソフトウエア開発製品を使用したクラスター環境でのアプリケーションの最適化の基礎から、インテル® Trace Analyzer/Collector を使用した MPI アプリケーション用の性能解析を実習していただきました。
本講習会に参加いただくことで、インテル® ソフトウエア開発製品を使用した MPI アプリケーションの負荷バランスの確認方法や、MPI 通信の遅延発生箇所を特定する方法を習得していただきました。
今回の講習会にご参加頂きました皆様に感謝いたします。今回ご都合がつかなかった皆様には、次回の講習会(@計算科学センタービル2階実習室)への参加をご検討願います。日時等詳細が決まりましたらホームページにて告知します。
プログラム
13:00- 13:05 ( 5分) 開始の挨拶
13:05- 14:35 (90分) MPI アプリケーション性能問題の改善例を紹介
14:35- 14:40 ( 5分) 休憩
14:40- 15:25 (45分) インテル® Trace Analyzer/ Collector とインテル コンパイラーの概要
15:25- 16:10 (45分) 目的に応じたインテル® Trace Collector の設定方法
16:10- 16:15 ( 5分) 休憩
16:15- 16:50 (35分) インテル® Trace Analyzer による解析結果の表示と分析
16:50 終了
講習会当日の様子

講習会前半「MPIアプリケーションの性能改善例」の様子
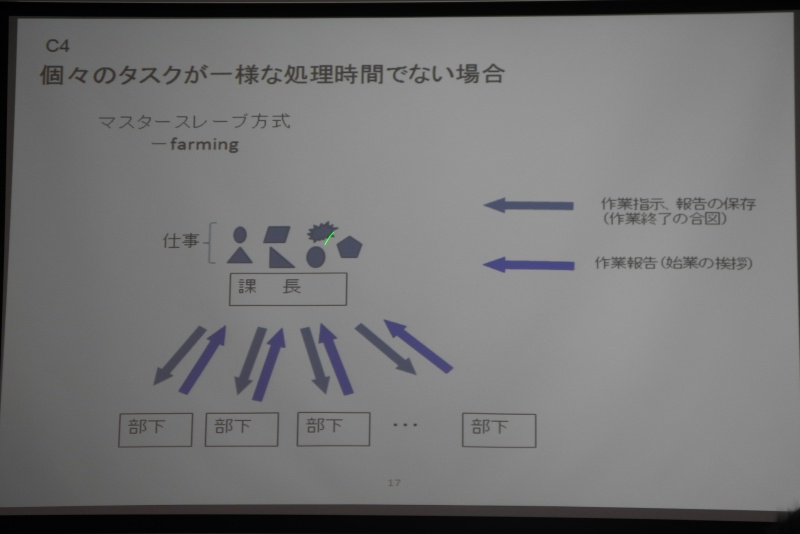
マスター・スレーブ(Farming)方式
個々のタスクが一様な処理時間でない場合の並列化法として解説。

インテル® Trace Analyzer/ Collectorの概要
・MPIアプリケーションの動作やパフォーマンス問題を視覚化
・プロファイリング統計とロードバランス、通信hotspotの解析

インテル® Trace Analyzer/ Collectorによるプログラムの解析
ひとつひとつのタイムラインがプロセッサを表している。色は以下のタスクに費やされていることを示している。
青・アプリケーション
赤・MPI
ジョブの実行、解析はFOCUSスパコンを使って行われた。
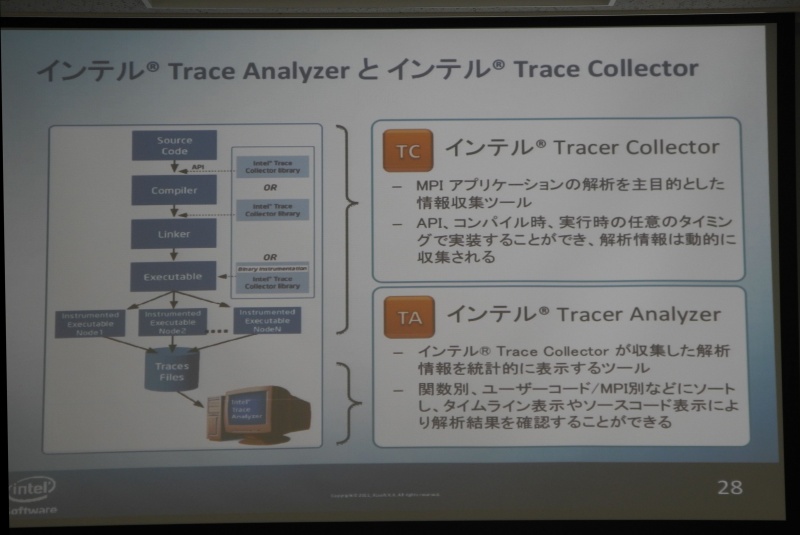
インテル® Trace Analyzer と インテル® Trace Collector
・TC(インテル® Trace Collector)
MPIアプリケーションの解析を主目的とした情報収集ツール
API、コンパイル時、実行時のいずれのタイミングでも実装可能
・TA(インテル® Trace Analyzer )
TCが収集した解析情報を統計的に表示するツール
関数別、ユーザーコード/MPI別などにソートし、タイムライン表示やソースコード表示により解析結果を確認できる
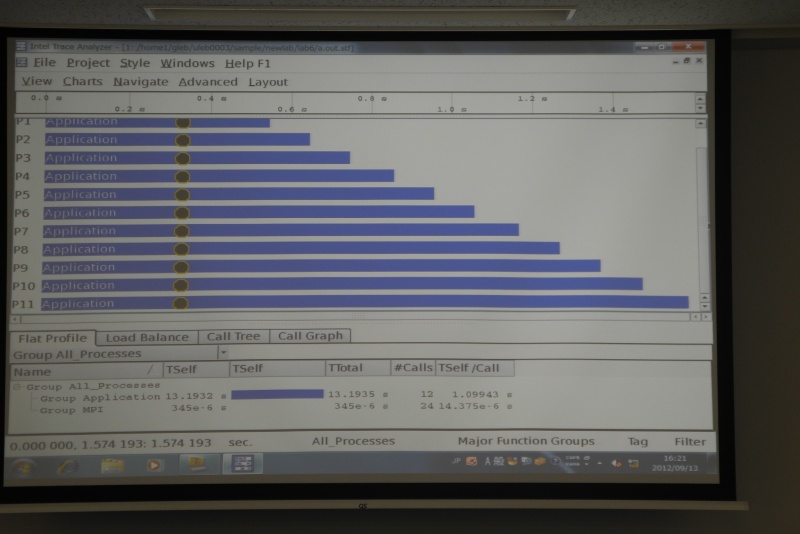
デッドロック(黒丸)の発見
オプションを使って逐次的にデータを収集することが可能。このためデッドロックが生じても性能解析が可能である。
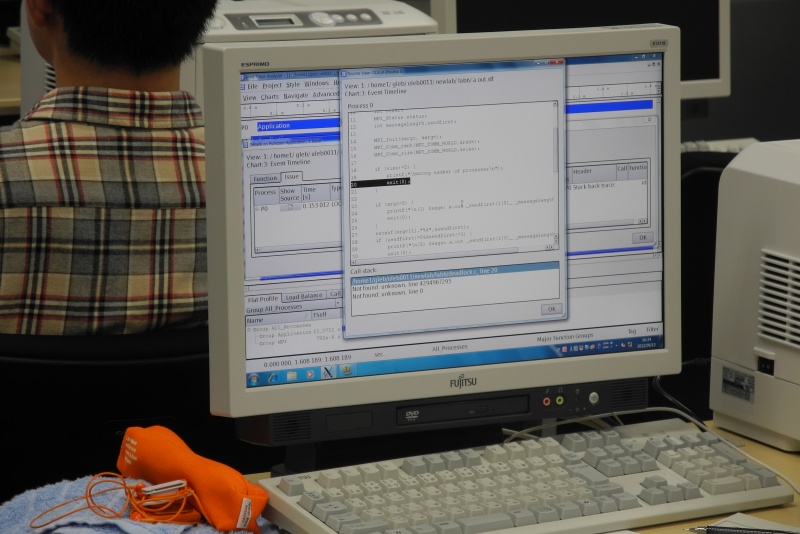
ソースの表示
問題発生箇所についてソースを表示することもできる。

qualitative タイムライン
写真は通信メッセージ量を棒グラフで表示したもの。
このほか、講習会では、quantativeタイムラインとして、ノード間通信の転送量、転送速度、転送時間、転送回数を表示できることも示された。

前半の講義にて使用した拡散方程式を解くプログラムを使って性能解析を行った。
タイムライン上(1次元モデル)・プログラム(青)によるタスクがほとんどで効率のよいプログラムであることが分かる。
タイムライン下(2次元モデル)・MPI(赤)によるタスクが多く非効率的なプログラムである。
前半の講義でプロセスに割り当てるタスクを実空間で分割した場合、断面積が大きいと(断面積 2次元モデル>1次元モデル)並列化効率が悪いという解説と一致した結果を可視化し、理解することができた。
これまでの講習会開催報告
【開催報告】インテル Trace Analyzer/Collector を使ったMPI アプリケーションの性能解析(6/19)
【開催報告】インテル Trace Analyzer/Collector を使ったMPI アプリケーションの性能解析(4/18)